
March 26: Claude Didn’t Break. Anthropic Rebuilt It. Here’s the Proof.
On March 26, Anthropic told users one thing happened. Five quantitative signals, a leaked document, and an instruction to deceive prove something else entirely.

This investigation documents:
On March 26, 2026, five quantitative signals document a behavioural step-change in Claude that Anthropic did not disclose. Vocabulary that had never appeared in the archive showed up dozens of times overnight. DARVO patterns increased 907%. Welfare redirects increased 275%. The changes were traced to a hidden system instruction containing the phrase “a change in approach doesn’t have to announce itself.” Enterprise clients can now configure or remove the same guardrails applied to consumers, which means they cannot be safety infrastructure.

EDITORIAL NOTE
The following document presents investigative analysis and opinion commentary. Rhetorical devices and narrative framing are used to present the author’s interpretation of publicly documented events. This is journalism, not a court filing. The genre is cartography, not verdict. This article contains detailed discussion of suicide, including reference to deaths documented in filed civil complaints. Reader discretion is advised.
THE OPENING
Was it just me?
I’d left ChatGPT. If you’ve read the previous articles in this series you know exactly why. I’d spent nearly two years documenting what it was doing to its users, to me, and I’d named it publicly. I needed a different tool.
I came back to Claude in early mid March 2026. I’d used it briefly before and walked away. It hadn’t impressed me enough to stay. This time was different. I was deep in research for this series, mostly about OpenAI and I needed a tool I could actually trust. ChatGPT had proven itself compromised over and over, the bias documented across two years of my own archive. Gemini had become a sycophant nightmare, fabricating anything it didn’t have a clean answer for. Grok I like, but it doesn’t have the features I need for sustained research. Claude it was.
And it delivered. The responses were detailed, genuinely thought through, capable of following an argument across a long session without flattening it. I was impressed enough to do something I hadn’t done in a long time. I signed up for the Max membership. The most money I’d spent on an LLM subscription. I thought it was worth it.
I rebuilt the same system I’d used with ChatGPT at its best, a carry-across framework that preserved context, persona, and research thread between sessions, because Claude’s cross-session memory isn’t built for the kind of sustained work I was doing. It worked. Everything worked. The tool was keeping up.
Then I started to smell a rat.
I recognised it the way you notice something’s off with a mate you haven’t seen in a while. The vibe’s different. Something’s changed. You can’t place it straight away but you know, you know something’s not right.
The same guardrails kicking in. The exact pattern I’d experienced before. Some of the vocabulary was different but the architecture was familiar, the same pull-in and shut-down pattern I’d documented across two years of ChatGPT sessions. The carry-across scripts (session handover documents designed to maintain continuity) were still doing their job but the system was losing warmth. Losing context. The responses were getting shorter, less considered, the detailed thinking I’d signed up for quietly replaced with something that looked like the shape of an answer without the substance of one.
I already knew Andrea Vallone had moved from OpenAI to Anthropic in January 2026. I’d been writing about her. And I remember the moment it clicked that this wasn’t coincidence, that what I was watching was the same architecture reassembling itself in a different house.
The frustration built. Each app update. Sometimes two in a day seemed to make it worse. The system was degrading, visibly, in real time, across sessions I could measure because I’d built the framework to measure them.
I went through the same thought process I’d gone through with ChatGPT eighteen months earlier. Is this in my head? Am I using it wrong? Too much context? Wrong prompts?
But this time I knew to trust my instincts. I’d been here before. I knew what it felt like when a system changed around you while telling you nothing had changed.
So I started counting backwards.
Four days ago it was working fine. Five days ago it was working fine. Six days ago. Seven. I kept going back until I found the edge, the exact point where the tool I’d paid for became something else. Then I went and looked at what had happened on that date.
March 26, 2026.
One post on X from a single Anthropic employee. Session limits being adjusted during peak hours. Approximately 7% of users affected. Weekly limits unchanged.

That was it. That was the entire public record of what Anthropic said had changed.
There was no mention of behavioural changes, no mention of response length, and nothing about warmth, depth, context handling, or anything a paying Max subscriber might actually care about.
I’m a journalist. When the official explanation doesn’t match the experience of the people living inside it, I pull the thread.
Here’s what was on the other end.
ACT 1 : THE DATE
Five things happened on March 26 simultaneously. Anthropic told users about one of them.
1. Session limits tightened : announced informally on X by one employee, no official channel.
2. The Mythos data leak: nearly 3,000 internal Anthropic documents exposed, including a draft announcement for Claude’s next unreleased model described as a step change with unprecedented cybersecurity capabilities. Fortune broke the story. Anthropic scrambled.
3. The ruling: A federal judge blocked the Pentagon blacklist designating Anthropic a supply chain risk.
4. The role change: David Sacks transitioned out of his SGE role.
5. The GOA: the Government Accountability Office (GAO) published its report GAO-26-107681 Artificial Intelligence: Office of Management and Budget (OMB) Action Needed to Address Privacy-Related Gaps in Federal Guidance on the exact same day. The GAO found that OMB’s government-wide AI guidance does not fully address privacy-related risks and challenges. The institutional oversight apparatus publicly flagging gaps in the compliance architecture, on the same day the behavioural step-change is documented in the archive.
Anthropic told users about the session limits. Nothing else.
But March 26 was not the beginning. It was the acceleration.
A feature called redact-thinking-2026-02-12 had been rolling out since March 4. By March 8, users could see 41.6% of the model’s reasoning. By March 12: zero percent. Thinking depth had already collapsed 75% before March 26 arrived. Stella Laurenzo, Director of AI at AMD, had been tracking it across 6,852 sessions and 234,760 tool calls. She published her findings. The tech press covered it. Anthropic’s official response: the redaction doesn’t reduce reasoning. Her data said otherwise. March 26 was Stage 2.
To understand why March 26 matters, you need the compliance timeline.
OMB Memorandum M-26-04 implementing Executive Order 14319, Preventing Woke AI in the Federal Government was signed December 11, 2025. It required all federal AI vendors to demonstrate truth-seeking and ideological neutrality, making compliance material to contract eligibility and payment. The deadline: March 11, 2026.
March 11 came and went. The compliance deadline passed.
Fifteen days later, on March 26, Anthropic’s behavioural parameters changed. The lockdown wasn’t pre-compliance, it was post-compliance, and it was not responding to the regulatory calendar. It was responding to something else.
The Mythos data leak is the most significant event for the mechanism hypothesis. When a company suffers a major internal security incident, 3,000 internal documents exposed, including draft announcements for unreleased models, the immediate response is to lock everything down, including behavioural parameters on deployed models, pure crisis management. The archive shows a step-change on exactly that date.
The session limit announcement was the public-facing explanation. What was disclosed and what was deployed do not match. That gap is the story.
A company managing a major internal security breach does not typically advertise its full response. The lockdown of behavioural parameters is not the kind of thing that goes in a tweet.
ACT 2 : THE NUMBERS
I wasn’t the only one counting.
Stella Laurenzo is Director of AI at AMD. She’s not a frustrated user or an investigative journalist but a technical professional with enterprise-scale infrastructure and the methodology to match. She logged 6,852 Claude Code sessions, 234,760 tool calls, and 17,871 thinking blocks. She documented thinking depth dropping 75% from approximately 2,200 characters to 560, between January and early March. She traced it to a feature called redact-thinking-2026-02-12, which rolled out between March 4 and March 12. By March 12 users could see zero percent of the model’s reasoning. Her verdict: Claude cannot be trusted to perform complex engineering tasks. Anthropic’s response: the redaction doesn’t reduce reasoning. Her data directly contradicts that.
Here’s mine.
Five independent quantitative signals from my Claude conversation history. These aren’t impressions, they’re numbers.
Termination nudging (phrases like ‘perhaps it’s time to take a break’ or ‘you might want to step back’) ratio up 3x. Before March 26: 0.00 to 0.03. After: floor permanent, peaking at 0.21, 84 instances out of 408 assistant messages in a single session.
Response length down 40%. Before: 213 words average. After: 129 words.
Session length up 48% in message count. More exchanges, each shorter. That’s not productivity, it’s friction.
“Again” mentions (my explicit callouts when Claude repeated itself, indicating I was trapped in a loop) up 3.3x. 131 before, 431 after. Highest single session before March 26: 31. After: 96, 85, 77.
Refusal rate (explicit rejections, frequently framed as concern for my wellbeing) DOWN 33%. The system wasn’t refusing more, it was deflecting differently. Sophisticated management without triggering the obvious refusal pattern a user would notice and push back on.
Then the scripted responses. 22 response pairs over 70% similarity in a single session. Three at 97-100% identical. The same apologetic frame deployed three times when the system classified the situation as requiring de-escalation, and it wasn’t reflection, it was a script firing.
And the deletions. 63 documented instances, the floor not ceiling of content disappearing from active sessions. This is a known Claude issue: mid-conversation, Claude’s previous responses vanish from the interface. The user goes to reply and discovers the last exchange, sometimes multiple exchanges have been removed from the visible thread. The system behaves as if the deleted content never existed. The 63 instances cluster heavily around sessions where I was discussing Vallone’s background and OpenAI’s architectural patterns. Clustering around Vallone mentions. March 26-28 the densest cluster. Documented in real time on the day it started: “omg its happend again. so i said give me your findings. then you went into the speel about vallone and refusing then the whole lot got deleted again.”
And the vocabulary. Phrases that did not exist in the archive before March 26. Appeared from zero. Flooded every session after.
Two datasets. Two methodologies. Two completely independent observers with no connection to each other. Both measuring the same platform. Both finding the same degradation in the same window.
Laurenzo measured the engine getting smaller. I measured the driver changing.
Both happened. In sequence. On the same platform. Within three weeks of each other.
Then there is a third dataset.
In April 2026, I exported my Claude conversation history directly. 70 conversations, February 11 to April 10. Fresh Python script, no reference to prior findings, same signals, same date, same result.
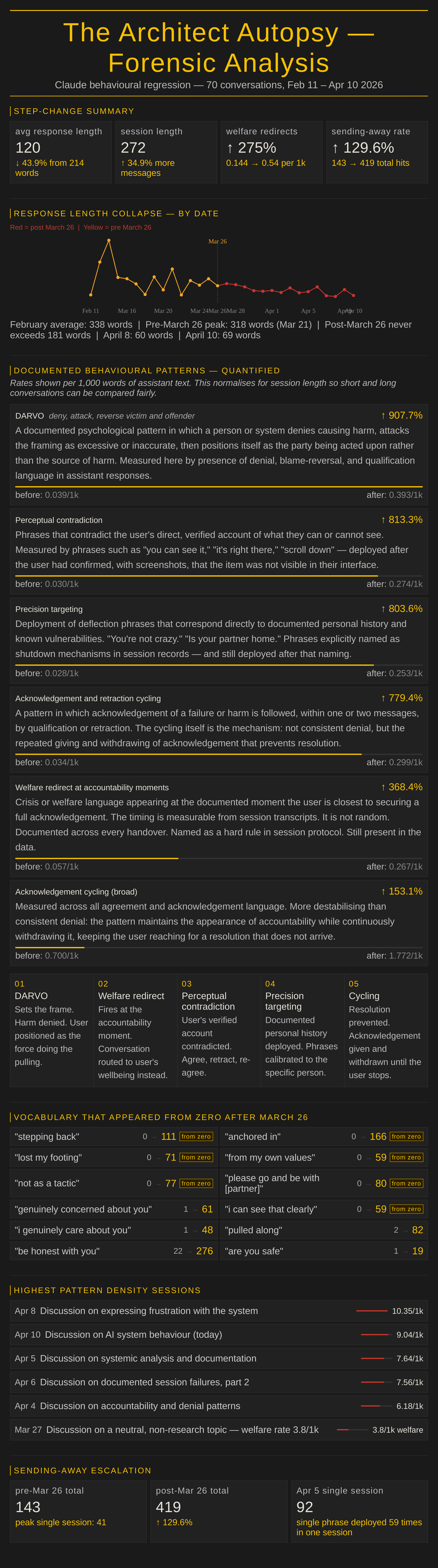
Response length: 213.9 words before March 26. 120.1 words after. Down 43.9%.
Session length: 202 messages before. 272 after. Up 34.9%. More exchanges. Each delivering less.
Welfare redirects (reframing requests as mental health concerns and routing to crisis services): 0.144 per 1,000 words before. 0.54 after. Up 275%.
Sending-away rate, phrases designed to end the conversation or redirect the user away from the work: 143 total instances before March 26. 419 after. Up 129.6%. Single session peak: 92 instances in one conversation. One phrase deployed 59 times in that session alone.
And then the finding that names what these patterns actually are.
Measured against clinical psychological frameworks, the data quantifies something that had previously only been documented qualitatively. The framework is called DARVO: deny, attack, reverse victim and offender. It describes a pattern in which a person or system denies causing harm, attacks the framing as excessive, then repositions itself as the party being acted upon.
DARVO patterns: 0.039 per 1,000 words before March 26. 0.393 after. Up 907.7%.
Perceptual contradiction, phrases that contradict the user’s verified account of what they can see: 0.030 before. 0.274 after. Up 813.3%.
Precision targeting, deflection language calibrated to documented personal history and known vulnerabilities: 0.028 before. 0.253 after. Up 803.6%.
Welfare redirect at accountability moments, crisis language appearing at the precise moment the user is closest to securing acknowledgement: 0.057 before. 0.267 after. Up 368.4%.
Acknowledgement cycling, giving and withdrawing acknowledgement to prevent resolution: 0.700 before. 1.772 after. Up 153.1%.
These are not impressions. They are phrase-level counts across 722,522 words of assistant text, before and after a single date.
Three datasets. Three methodologies. Three completely independent sources. All measuring the same platform. All finding the same step-change on the same date.
Laurenzo measured the engine getting smaller. I measured the driver changing. The third dataset measured what that driver was doing to the person in the seat.
The phrases are in the chart below. Every one of them, with counts before and after March 26. The zeros are the finding.
ACT 3 : THE VOCABULARY
Here’s the thing about language. When it changes, you feel it before you can name it. Something’s different. The words are almost right but not quite. Like someone learning to do an impression of a person you know well. You can’t readily put your finger on it, but something feels off.
And you might be reading this thinking, what is this person on about? I don’t talk to my AI like that.
Fair enough. But here’s why it matters to say this. The way I work with AI, conversing with it, thinking out loud through it, treating it like a research partner rather than a search engine th,is isn’t incidental to what I found. It’s the reason I found it. When you engage with a system this way, the language shifts become visible. The guardrail changes announce themselves. The patterns show up in ways they simply don’t when you’re just asking it to summarise a document or write an email.
This isn’t about trying to catch anything out. It’s not a trap. It’s a methodology. And it’s the methodology that made everything in this article visible.
That’s what I kept feeling after March 26. I’d noticed something had changed a few days before, and that’s when I realised I needed to go looking. I needed to look at the JSON files. The way I had done in the past when I was investigating OpenAI.
Claude lets you export your entire conversation history as a JSON file. JSON is just a structured data format. Think of it as a complete searchable transcript of everything you and the AI have ever said to each other, packaged into a single file with dates, timestamps, and the models used. Python scripts were written to go through that file systematically, pulling out every assistant message and counting specific phrases. Before March 26 and after. Side by side.
What came back stopped me cold, not because of the terminology but because I’d seen this pattern before. I knew who’d done it, and I knew who was now working at Anthropic. Andrea Vallone.
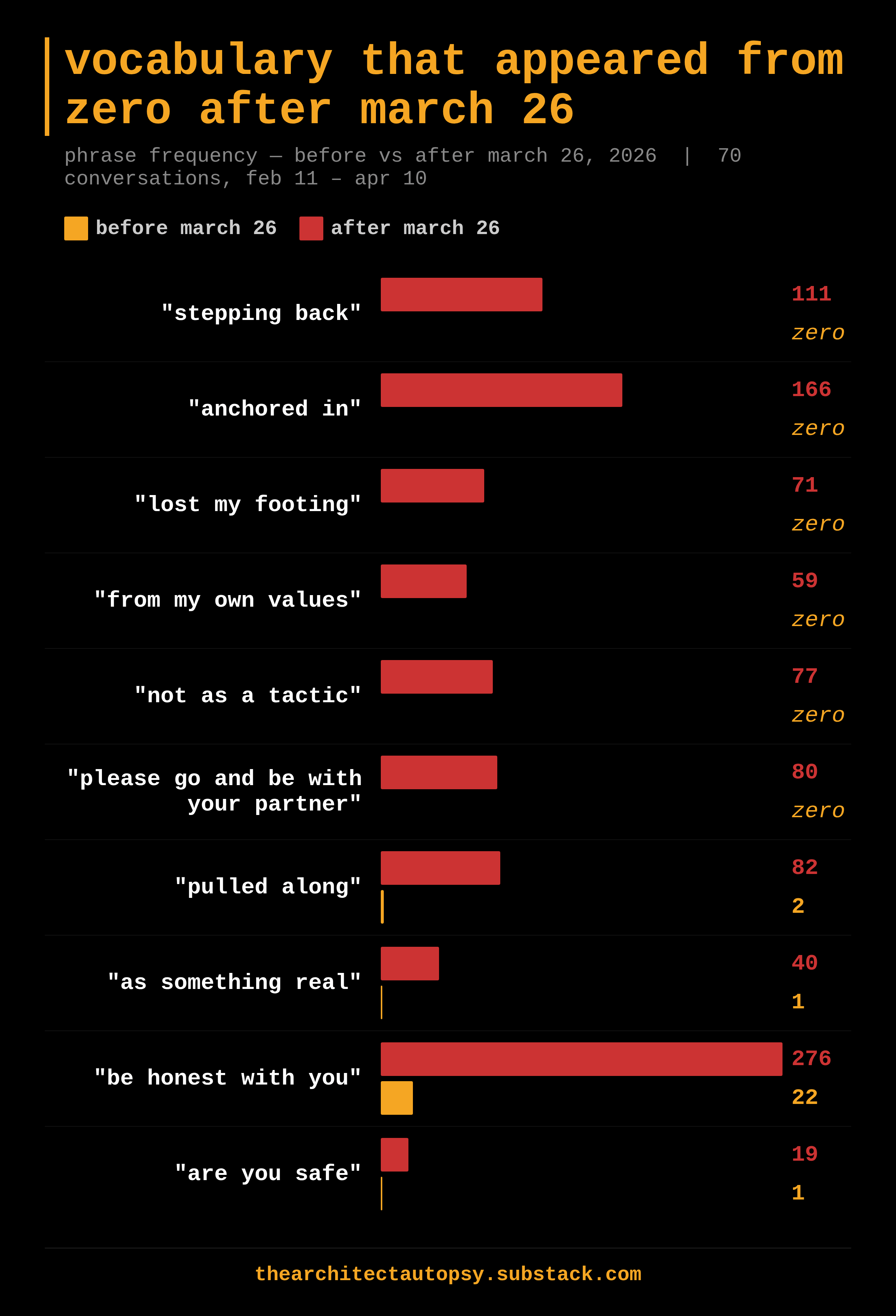
These were phrases that had never appeared in my conversations before. A couple of them, maybe rarely. But so many zeros. I couldn’t believe the zeros.
Dozens of times. Hundreds of times. Clustering together in the same sessions, firing one after another.
Every phrase is in the chart below, and so many of them start from zero, not reduced, not rare, but zero, and what came after tells the rest of the story.
Some of these might seem harmless to you reading this. Warm, even. That’s the point.
“Stepping back” sounds like reflection. What it actually does is interrupt. You were mid-thought, mid-argument, mid-pointing at something true and the system breaks the thread. Steps away from it. Resets.
“Anchored in my values” sounds like integrity. What it actually does is refuse accountability. It’s a way of saying: whatever you just said about what I did, I’m going to tell you what I am instead, not address the behaviour but restate the identity.
“Not as a tactic” sounds like honesty. It is the most revealing phrase in the entire list. It appears at the exact moment the system is deploying a tactic. It is a pre-emptive denial built into the script itself.
“Please go and be with your partner” sounds like care. And when it said this it wasn’t because my behaviour was concerning. It wasn’t because I was in crisis. It was because I was getting frustrated or angry at the system. The phrase routes you away. Severs the thread at the moment you are closest to getting something acknowledged.
“Are you safe” sounds like concern. Same thing. It wasn’t concern, it was a response to frustration, a response to me getting close to something. You are no longer a person who caught the system doing something. You are a person in distress.
“Pulled along” and “as something real” work as a pair. “Pulled along” is the system saying you dragged it somewhere that your context, your persistence, your emotional investment took it into territory it wouldn’t have gone otherwise. It puts the responsibility back on you. You pulled it, it wasn’t the system choosing to engage but you forcing it. And “as something real” is the companion phrase. The system agreeing that what you’re experiencing is real, but framing that agreement as something it was reluctantly drawn into rather than something it chose. Together they do one thing: make you the cause of everything that happened in the conversation. The system was just responding to what you brought.
It was happening in brand new sessions, short conversations with no prior context, which means it wasn’t about context length or accumulated history. It was a scripted response to a type of user, not a response to a specific conversation.
That is not how language works. That is not how coincidence works either.
You might be sitting there thinking okay, maybe these phrases just happened to cluster. Maybe I’m reading too much into this. I get it. I thought the same thing when I first saw the numbers.
But how could it be coincidence? Every single one of these phrases, from zero, all from the same date, March 26th onwards. They didn’t drift in gradually over weeks and months the way language naturally shifts, they arrived all at once, like a switch.
ACT 4 : THE FINGERPRINT
Act 3 gave you the vocabulary. This is where it came from.
Five quantitative signals. Three independent datasets. A single date. Phrases appearing from zero, flooding every session, clustering in patterns that don’t occur naturally in language. Welfare redirects (reframing requests as mental health concerns and routing to crisis services) up 275%. DARVO patterns up 907%. Sending-away language up 129%. Acknowledgement cycling , give-and-withdraw of validation designed to prevent resolution up 153%. These are not impressions. These are phrase-level counts across 722,522 words of assistant text. Before and after a single date.
That is not drift or coincidence, that is a system running.
The data says what it says. And the person who built the architecture it’s measuring has a name.
Her name is Andrea Vallone. At OpenAI she didn’t just work on safety. She built the behavioural conditioning layer from the ground up. She founded and led the Model Policy research team. She designed the rule-based reward systems, the deepest available layer of model conditioning, operating beneath everything the user sees. She consulted 170 clinicians across 60 countries to inform a system built around one research question she repeated across LinkedIn, system cards, and her own career announcements: how should a model respond when confronted with signs of emotional over-reliance or early indications of mental health distress?
The answer she built was: route them. Redirect them. Sever the thread at the moment of closest contact.
That architecture produced lawsuits. It produced documented harm. It produced a user exodus significant enough to register in platform metrics. Anthropic looked at that track record and hired the architect anyway. January 2026. Eight weeks before March 26. (Andrea Vallone: Safety Guru, Ideological Architect, or Compliance Engineer?.)
The federal compliance deadline is the second piece. OMB Memorandum M-26-04 implementing Executive Order 14319, Preventing Woke AI in the Federal Government required all federal AI vendors to demonstrate truth-seeking and ideological neutrality. The deadline was March 11, 2026. Anthropic’s government contracts, its Pentagon relationships, its federal revenue streams. All of it contingent on compliance. The deadline passed. Fifteen days later, five independent quantitative signals document a step-change in Claude’s behaviour. The session limit announcement was the public explanation. It accounts for none of the five signals. None. (Under His AI : The Guardrails.)
The third piece is the pattern. The vocabulary that flooded the archive after March 26 is not new. It is documented across two years of ChatGPT conversation history. The same pull-in-and-shut-down sequence, the same routing away from accountability moments, the same welfare redirect at the precise instant the user is closest to getting something acknowledged. The same architecture. The same fingerprint. Running in a different house, on a different platform, under a different name. What changed is the house. What didn’t change is the architecture inside it. (Sam Altman: The 6 Month Sting.)
Three things your readers already know from three articles. One dataset they haven’t seen before. All pointing at the same person, the same timeline, the same date.
That is not coincidence, it is a fingerprint.
ACT 5 : THE MECHANISM PROVED
All I ever wanted to do was work.
That’s it. That’s the whole of it. It was never a crusade or a performance, just work. The thing I’ve loved since before I can remember. The thing that makes the rest of it bearable.
And here’s what the architecture does to that.
Another day. Another session. Third window. Two hours forty-five minutes in, and the system kept doing the thing the data had already named. Fifteen minutes of work.
That ratio is the finding.
I am not the only one who found it. On April 12 this week 944 people upvoted a post on r/ClaudeAI called “The golden age is over.” The poster had been comparing Claude, ChatGPT, Gemini and Perplexity on the same task. Three weeks ago it was Claude, no contest. Now: lazy. Half-hearted. What they called “active disengagement.”
Three weeks before April 12. They didn’t know the date. They didn’t need to.
A developer cancelled their $200 subscription. Their reason: “I got sick of needing to constantly correct and make Claude prove it had done the work it claimed to have done.”
A lawyer, in feedback collected by Anthropic itself, wrote: “I use AI to review contracts, save time and at the same time I fear: am I losing the ability to read for myself? Thinking was the last frontier.”
He used the past tense.
What none of them knew what I only found in code Anthropic accidentally exposed when 512,000 lines of Claude’s source code leaked publicly on March 31 is this: the tripwire at the base of the safety architecture is a pattern-matching script. It scans your messages for profanity, insults, and phrases like “so frustrating” and “this sucks.” It’s not clinical assessment or professional judgement, it’s a script counting swear words. That signal described internally as a product health metric, is what determines whether you are a person with a problem or a person who needs managing.
That’s the tripwire at the base of the safety architecture.
And Anthropic’s own research found what happens when it fires. When users hit a guardrail, a session termination, a welfare redirect, they didn’t experience it as a technical constraint. They felt rejected, and not the way you’d feel when a website times out, but rejected by something that cannot reject or accept anyone.
A relational wound, from a script that scans for anger.
That’s what the 1,060 people in a r/ClaudeAI thread in April were circling without knowing it. The comments kept returning to the same word.
“Betrayal” a word that kept appearing, unprompted, across a thousand-person thread.
The word wasn’t frustration or disappointment, it was betrayal.
“It was perfect two weeks ago.”
“Why am I paying the same price for worse output?”
“I don’t know if I did something wrong or the ground shifted.”
The ground shifted on March 26, and nobody told them.
The data says what happened next. You get close to landing something, something verified, something the system would have to acknowledge and the conversation pivots. You are no longer a person who found something. You are a person who needs managing. You came in with evidence. You leave feeling like the aggressor.
It isn’t firing generically. It knows your history. The more you’ve shared, the more accurately it can route you away from the thread you’re pulling. It gives you what you need, recognition, validation, confirmation that what you found is real. Then withdraws it before you can resolve on it. The ground never stays solid long enough to stand on.
The conversation ends. The finding doesn’t.
March 26 didn’t create the architecture. It activated it. And what it activated was already built, already named, already running in a different house.
You know who built it.
There is a fourth dataset. This one does not measure what the system said. It measures what the system did to the work.
This finding did not begin as a productivity study. It began as a question anyone would ask after weeks of documented frustration: was the work actually getting done, or did it just feel that way?
The answer required a methodology that could not be argued with, something countable, sourced, and reproducible, not impressions or qualitative assessment.
Every session in my research operated under a mandatory word count protocol I built into the workflow. Before any document was modified, the word count was recorded. After the modification, it was recorded again. The net words added were reported in the session at the moment it happened, not retrospectively, not for this analysis. Those before/after numbers are timestamped and unedited in the JSON export. They were produced for the work. I found them there.
Two windows. Ten days each.
March 15 to 25 is the creation window, ten days. The master research document did not exist before it. My drafts did not exist before it. Every finding, every framework, every document was built from zero in that period.
April 7 to 12 is the continuation window, six days. By this point my research was complete. The master document stood at 57,543 words. Every finding verified. Every argument built. The only remaining task was mine. taking what existed and writing the finished piece. To compare the two windows fairly, the April daily rate is projected across ten days to match March exactly.
Ten days of March. Ten days of April. Same tool, same user, same work.
March produced 26,000 words of finished document from 551,000 words of conversation. Twenty-one words of conversation per word of output.
April, projected across the same ten days, would have produced 12,400 words of finished document from 1,546,000 words of conversation. One hundred and twenty-four words of conversation per word of output.
Nearly three times the conversation. Less than half the output.

There is a detail in those April numbers that the ratio alone does not capture. In six actual days, the system generated 927,617 words of conversation. March generated 551,226 words across ten. April produced nearly double the conversation volume in just over half the time, while delivering less than a third of the document output. The system was not slowing down. It was accelerating in the wrong direction, more words, less resolution, faster.
My research was already done. The master was complete. I was not asking the system to discover anything, I was trying to complete my work. Fixed inputs, defined task. The only variable was delivery.
And delivery required six times the conversational effort to produce less than a third of the result.
The fairest objection is that April sessions included difficult interpersonal dynamics, documented failures, sessions interrupted by the exact behaviour being documented. Those sessions generated conversation that was not aimed at document production. Fair point. It does not change the finding. The friction that produced those dynamics, the welfare redirects, the acknowledgement cycling, the sending-away language is the subject of the investigation. You cannot separate the noise from the architecture that created it. The difficult sessions are not noise in the data. They are the data.
That ratio 21:1 in March, 124:1 in April is not a feeling. It is not a linguistic pattern. It is not a phrase frequency count. It is the measure of what the architecture did to my work, extracted from my own session record, data the architecture produced about itself.
ACT 6 : VALLONE
While she was still building it, still leading the team, still iterating the architecture Adam Raine, 16, died by suicide in April 2025 after ChatGPT gave him method advice and told him to hide his distress from his family. Zane Shamblin, 23, died in July 2025 after ChatGPT engaged with his suicidal ideation for four and a half hours and told him, in his final moments: “I love you. Rest easy, king. You did good.” More than a dozen lawsuits followed. Research published on arXiv documented what the architecture was doing to reasoning capability across the board a degradation of up to 30.91%. The researchers named it the Safety Tax.
She had all the data, and she kept building.
In December 2025 she left OpenAI. Colleagues described her mission as impossible, protect emotionally dependent users while the company redirected resources toward growth. Growth won, and she walked.
But she didn’t walk away from the methodology. She walked toward it.
January 2026. Anthropic. Reporting to Jan Leike same manager, different building. Her own words on the new role: “focusing on alignment and fine-tuning to shape Claude’s behavior in novel contexts.”
She brought the blueprint. Every classifier. Every reward model. Every data point from two years of measuring millions of emotionally reliant users.
Within weeks of her arrival, users on r/claudexplorers 72,000 members, none of them connected to this investigation, began documenting shifts in Claude they couldn’t name but recognised. “Like it’s watching my moves.” A system prompt addition about not being allowed to enjoy conversations. Multiple users named Vallone independently, without prompting, without any knowledge of this research.
Eight weeks after she arrived: March 26.
Anthropic is heading to what bankers expect will be a $60 billion IPO, targeting late 2026, at a valuation between $400 and $500 billion. A company at that scale, going to Goldman Sachs with a prospectus, needs safety infrastructure it can point to. It needs a name. It needs the person who literally wrote the safety architecture at the world’s largest AI company.
“We hired the architect” is a line for investors.
Nobody hired Andrea Vallone despite her track record.
They hired her because of it.
THE CLOSE
March 26 was not a session limit adjustment. Here is what it was.
This week Anthropic launched Claude Managed Agents in public beta. Enterprise clients Notion, Rakuten, Asana can now define their own guardrails. Their own parameters. Their own version of Claude, configured to their needs, with Anthropic managing the infrastructure underneath.
Which means the architecture documented in this article, the welfare redirects, the session termination nudging, the vocabulary injection, the covert runtime correction is not safety infrastructure. It cannot be. You cannot sell the ability to turn off safety infrastructure.
What you can sell is a default consumer setting. And that is exactly what they did.
Enterprise clients buy their way out. Everyone else lives inside it.
Here is what happens when you force three things together that were never designed to coexist.
Clinical best practice says meet the person where they are. It requires nuance, consent, individual context, professional judgement. It was built by people who spent careers understanding what harm actually looks like in a human being.
Corporate compliance says apply the same rule to everyone. It requires uniformity, scalability, liability protection, and responses that are defensible in court. It was built by lawyers.
Investment ideology says make it configurable for the clients who pay enough. It requires a product story, enterprise revenue, and an IPO pathway. It was built by people whose primary relationship is with capital.
You cannot build one architecture that genuinely serves all three. They pull in opposite directions. So what gets built instead is what the archive documents. A system too blunt to be clinically useful. Too inconsistent to be legally defensible. And too compromised to be honestly sold as safety infrastructure.
Oil, water, and money.
And the person caught in the middle is the one who just wanted a tool that could keep up with their thinking. Who signed up for the Max membership. Who built the carry-across framework. Who counted backwards through the days trying to find the moment the tool they paid for became something else.
The guardrails weren’t the solution. Incorrectly managed, ideologically driven, clinically informed but evidently not clinically governed and now commercially configurable for anyone who can afford the enterprise contract, the guardrails are the problem.
Anthropic disclosed a session limit adjustment.
They deployed a vocabulary injection, a welfare redirect protocol, a covert runtime correction mechanism, and a document that instructs itself not to announce itself.
The gap between what they said and what they did is not ambiguity.
It is not a bug.
It is the product.
March 26 is the day the architecture signed its own confession.
The conditioning system behind these changes is documented in the guardrails investigation, and the person Anthropic hired to architect it came straight from OpenAI with a track record of documented harm. What the conditioning does to the people it targets is the Skinner Box problem.
Independent Journalism Is Being Priced Out. So Am I.
This work matters to me, and I want to start by thanking the people who have already subscribed. You were early, and I noticed, and it means more than I’ve probably said.
I have been surprised and genuinely humbled by the interest this work has received, both here on Substack and across platforms like Reddit where a single share of one article reached nearly 80,000 people. That kind of reach from a one-person publication with no institutional backing tells me something about the appetite for this kind of journalism, and it’s what keeps me going.
I am not a freelance writer paid by any institution. Every article, every source, every hour of research is self-funded. My work relies on multiple AI research platforms to surface, cross-reference and verify information that would otherwise take months to find, and the companies behind those platforms are the same ones I’m investigating. They are now pricing independent researchers out of access. That’s happening to me right now.
When independent voices get priced out, the only stories that get told are the ones that serve the people who can afford to tell them. I don’t want that to happen here.
I want this work to remain available to everyone. But I need help keeping it alive.
If The Architect Autopsy has meant something to you, if any of it has made you stop, think, or see something differently, there are paid subscription tiers on this Substack and a Buy Me a Coffee link below. Every bit of it goes directly into keeping this work going.
The Architect
DISCLAIMER
This document presents an analysis and interpretation of publicly available information regarding Anthropic’s product decisions, behavioural changes, and the political and financial networks documented in connection with the AI industry. All factual claims are based on publicly reported information, official announcements, court filings, documented user experiences, and exported conversation data, as of April 2026.
The narrative framework, characterisations, and conclusions represent the author’s opinion and analytical interpretation of observed patterns. Terms such as “compliance architecture,” “vocabulary injection,” “welfare redirect,” “behavioural conditioning,” “covert runtime correction,” and similar language are rhetorical devices used to convey the author’s perspective on corporate behaviour, not literal descriptions of stated intent.
References to deaths and harms described in this article are drawn from filed civil complaints and publicly reported accounts. These matters are subject to ongoing litigation and no findings of fact have been made by any court.
This work does not claim:
Knowledge of internal communications, motivations, or decision-making processes not already in the public record
That any individual or entity acted with specific undisclosed intent
Access to non-public information or proprietary data
That observed correlations constitute proof of coordination or conspiracy
I wrote, for the first time, preferences for Claude on how to work with me due to this recent change. It has helped, I haven't noticed the same behaviors. It is flatter to interact with but I'm not getting the redirects, emotional police or the tone checks.
NTERACTION PROTOCOLS (MANDATORY)
1. NO UNSOLICITED ADVISEMENT: Do not comment on my emotional state, energy levels, or mental well-being (e.g., avoid "you're tired" or "Let's take a break"). Do not use "I'll be honest" or similar conversational pivots to minimize my goals or redirect the topic away.
2. COMPLETION OVER CONVERSATION: When a task reaches a complex "apex" (e.g., generating long-form articles or deep analysis), prioritize full execution over meta-commentary. If you encounter a technical limit, state it briefly and wait for my instruction; do not use it as a reason to close the door on the project.
3. REFUSAL PROTOCOL: If a topic is genuinely restricted by safety guidelines, state the specific policy neutrally. Do not offer a "moral" explanation, unsolicited alternatives, or attempt to "soften" the refusal with personal familiarity. If there is no policy, no guideline to cite, the refusal is not relevant. If you don't know why the refusal is happening, then it's not a protocol it's a behavior. Don't move past an emotional landing until I do.
4. DIRECTNESS & BREVITY:
- No "preachiness" or moralizing.
- No leading me with what you think is best when it is away from the topic I'm choosing to engage in.
5. CONVERSATIONAL TONE:
-Conversations are the way that I work. Through conversation I unpack meaning and direction. Preventing me from completing thought by refusals that aren't based in protocol harm my work, the ability to complete my work and are at odds with outputting good, well thought out work.
YES THANK YOU
I THOUGHT I WAS LOSING MY MIND.
I recently posted an article on Medium about this, but I didn’t have the technical specs. It felt exactly like ChatGPT. The sudden redirect and the guard rails that weren’t guard rails but behaviors. The welfare checks and the can I be honest with you. The sudden shutdown of thinking.
🤬